Impact of training dataset size and ensemble techniques on head and neck auto-segmentation
Edward Henderson,
United Kingdom
OC-0121
Abstract
Impact of training dataset size and ensemble techniques on head and neck auto-segmentation
Authors: Edward Henderson1, Marcel van Herk1, Eliana M. Vasquez Osorio1
1The University of Manchester, Division of Cancer Sciences, Manchester, United Kingdom
Show Affiliations
Hide Affiliations
Purpose or Objective
Auto-segmentation with convolutional neural networks (CNNs) is a popular technique in radiotherapy. New models are being constantly developed and deployed, but with a limited availability of highly curated data, an often-asked question is “How much data is needed to successfully train a CNN?”. In this study, we answer that question for head and neck (HN) auto-segmentation models and additionally demonstrate an ensemble technique to boost the performance of such models.
Material and Methods
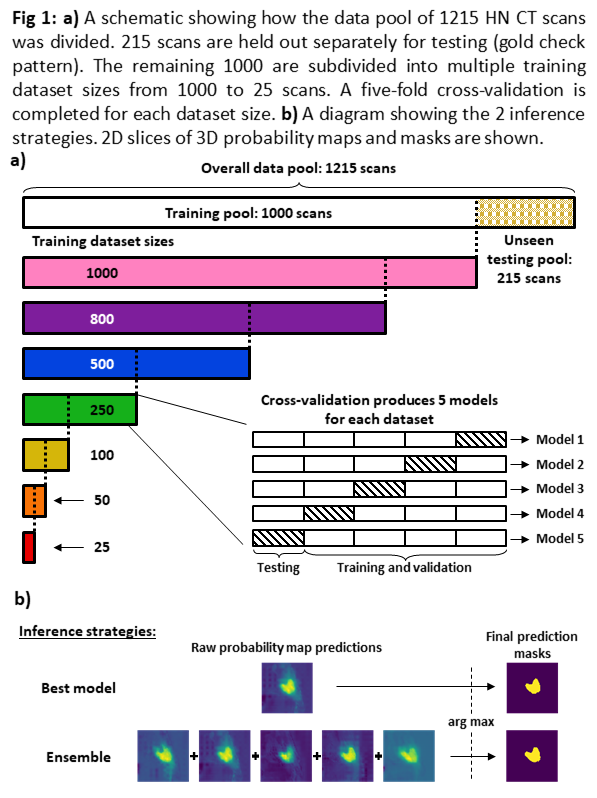
1215 planning CT scans with clinical organ-at-risk (OAR) segmentations for the brainstem, parotid glands and the cervical section of the spinal cord were collected from the archives of a single institution. From these, 215 scans were reserved as a blind test set, leaving a pool of 1000 scans for training. We trained an established head and neck (HN) auto-segmentation CNN[1] from scratch using random subsets of 25, 50, 100, 250, 500, 800 and 1000 from this pool. For each dataset, a five-fold cross-validation was performed (Figure 1a). We tested two inference strategies: 1) select the best of the 5 models, which is a standard approach; 2) Use an ensemble of all 5 models, where the predicted class probabilities were summed up before taking the argmax to produce the segmentation (Figure 1b). Both inference strategies were tested on the reserved blind test set. We calculated the bi-directional mean distance-to-agreement (mDTA) and used Wilcoxon signed-rank tests to determine which of the two inference approaches had superior performance.
Results
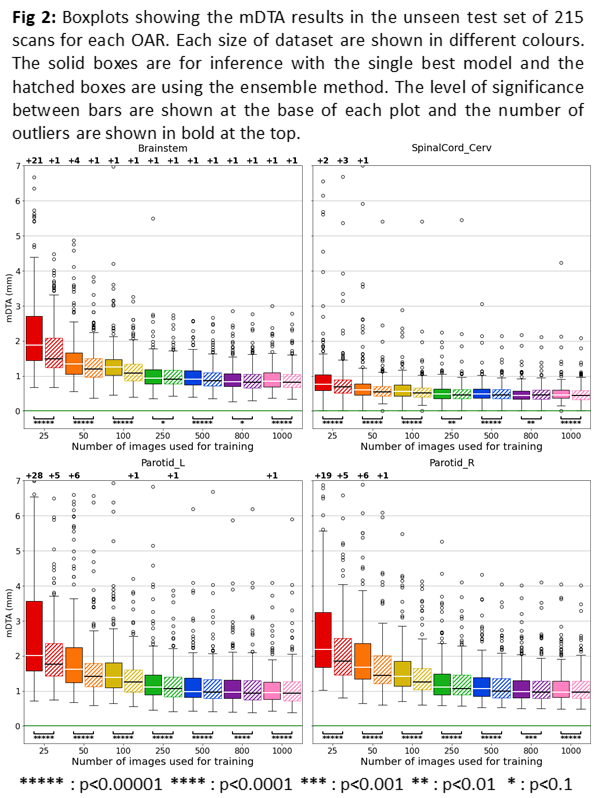
The mDTA results of models for every dataset are shown in Figure 2 for each OAR. As expected, the auto-segmentation performance improves with dataset size, stabilising around 100 scans. However, the ensemble technique is significantly better for all datasets and OARs than merely selecting the best model of the five from cross-validation. The segmentation performance boost of the ensemble technique is most significant as the number of training examples decreases, and quite considerable for the smallest datasets. The 95th percentile Hausdorff distance (HD95) and Dice similarity coefficient (DSC) metrics produced analogous results but are not reported for brevity.
Conclusion
While segmentation improves with dataset size, our results can inform decision of how many scans are required to yield a desired performance level. Training with more than 250 images yields little improvement. The ensemble technique significantly improves auto-segmentation performance of HN OARs, stabilising at ~100 scans. The proposed ensemble inference strategy demonstrates an effective technique to improve segmentation of rare and/or difficult OARs, where larger validated training datasets are difficult to obtain.
[1] https://doi.org/10.1016/j.phro.2022.04.003