Deep Particles Embedding: accelerating Monte-Carlo dose simulations
PO-1802
Abstract
Deep Particles Embedding: accelerating Monte-Carlo dose simulations
Authors: Sonia Martinot1, Nikos Komodakis2, Maria Vakalopoulou3, Norbert Bus1, Charlotte Robert4, Eric Deutsch4, Nikos Paragios5
1Therapanacea, Physics, Paris, France; 2University of Crete, Computer Vision, Heraklion, Greece; 3Centralesupelec, MATHEMATICS AND INFORMATICS, Gif-sur-Yvette, France; 4Institut Gustave Roussy, Radiotherapy, Villejuif, France; 5Therapanacea, CEO, Paris, France
Show Affiliations
Hide Affiliations
Purpose or Objective
The Monte-Carlo (MC) radiation transport calculation method remains the most accurate tool available to account for particles-matter interaction and therefore, for simulating radiotherapy dose distribution maps. However, without heavy approximations, the MC algorithm is too slow for clinical use.
In this work, we use Transformer positional embeddings (Vaswani et al. 2017) to create a framework that accelerates MC simulations using very low precision priors and improves on previous work on the same dataset.
Material and Methods
The dataset comprises MC dose distributions simulated from 50 patients treated with 2 arcs Volumetric Modulated Arc Therapy plans. The original volumes have a resolution of 2mm. The training, validation and test sets draw slices of dose volumes from respectively 35, 5 and 10 non-overlapping patients. In our setting, each patient has a high precision dose distribution simulated with 1e11 particles, and 3 low precision simulations computed with 1e8, 1e9 and 1e10 particles.
The model is a UNet (Ronneberger et al., 2015) with 2 downsampling stages in the encoder and also computes a sinusoidal positional embedding of the number of particles involved in the simulation of the corresponding input dose distribution. Overall the model has 10 million trainable parameters. During training, the model learns to infer the high precision dose from any of the 3 associated low precision distributions and associated positional embeddings. After training, the model can infer from any of these low precision distributions independently.
We train the model on complete slices extracted from the patients' dose volumes. Preprocessing consists in normalizing each dose map by the mean maximum dose computed over the reference distributions present in the training set. To enable batch training, we pad each dose map in the datasets to be 256x256. At inference, no padding is required. We apply random horizontal and vertical flipping as data augmentation during training. We use AdamW optimizer and the sum of the Mean Squared Error (MSE) and the Structural Similarity Index Measure (SSIM) as loss function.
Results
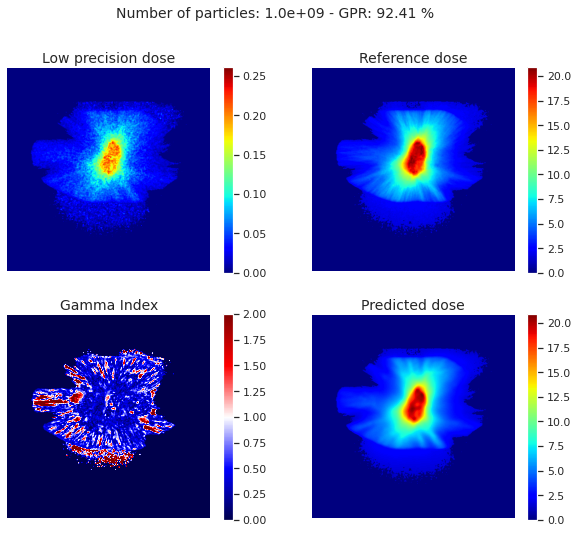
We evaluate the model using the Gamma Index Passing Rate (GPR), the Structural Similarity Index Measure (SSIM) and the Mean Absolute Error (MAE). For benchmark, we trained the same model using only one low precision simulation (1e9 particles) as input. The table and the figure show the results on the test set. The model outperforms others by at least 10% with respect to the GPR.
| Model input | GPR (%) | SSIM | MAE |
Benchmark 1e9
| 77.1±17.9 | 90.1±6.1
| 8.6e-1±3.0e-2
|
Mixed 1e8
| 61.4±6.6
| 74.3±7.2
| 1.1e-1±4.1e-2
|
Mixed 1e9
| 83.2±10.2
| 91.1±3.1
| 8.3e-2 +- 2.3e-2
|
Mixed 1e10
| 95.7±3.6
| 94.5±2.1
| 6.8e-2±2.1e-2
|
Martinot et al.
| 83.2±12.9
| 97.3
| N/A |
Conclusion
Using positional embeddings of the number of simulated particles in the MC simulations allowed for the model to extract more meaningful features and to outperform existing frameworks. The experiment showcases a new efficient way to accelerate MC computations using neural networks.